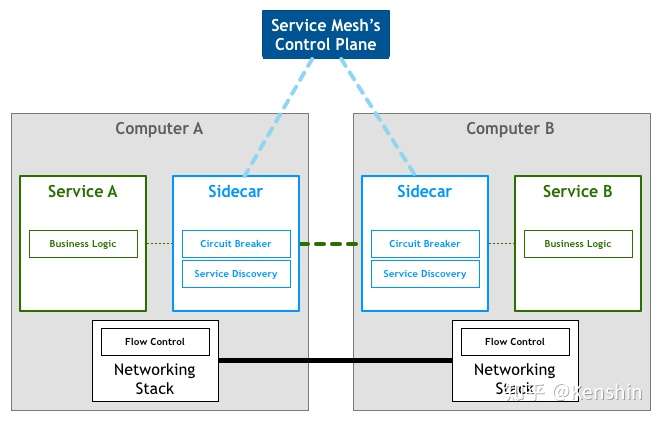
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
select distinct cert.emp_id from cm_log cl innerjoin ( select emp.id as emp_id, emp_cert.id as cert_id from employee emp leftjoin emp_certificate emp_cert on emp.id = emp_cert.emp_id where emp.is_deleted=0 ) cert on ( cl.ref_table='Employee' and cl.ref_oid= cert.emp_id ) or ( cl.ref_table='EmpCertificate' and cl.ref_oid= cert.cert_id ) where cl.last_upd_date >='2013-11-07 15:03:00' and cl.last_upd_date<='2013-11-08 16:00:00';
0.先运行一下,53条记录 1.87秒,又没有用聚合语句,比较慢
1
53 rows in set (1.87 sec)
1.explain
1 2 3 4 5 6 7 8
+----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where; Using temporary | | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 63727 | Using where; Using join buffer | | 2 | DERIVED | emp | ALL | NULL | NULL | NULL | NULL | 13317 | Using where | | 2 | DERIVED | emp_cert | ref | emp_certificate_empid | emp_certificate_empid | 4 | meituanorg.emp.id | 1 | Using index | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+
select emp.id from cm_log cl innerjoin employee emp on cl.ref_table = 'Employee' and cl.ref_oid = emp.id where cl.last_upd_date >='2013-11-07 15:03:00' and cl.last_upd_date<='2013-11-08 16:00:00' and emp.is_deleted = 0 union select emp.id from cm_log cl innerjoin emp_certificate ec on cl.ref_table = 'EmpCertificate' and cl.ref_oid = ec.id innerjoin employee emp on emp.id = ec.emp_id where cl.last_upd_date >='2013-11-07 15:03:00' and cl.last_upd_date<='2013-11-08 16:00:00' and emp.is_deleted = 0
4.不需要了解业务场景,只需要改造的语句和改造之前的语句保持结果一致
5.现有索引可以满足,不需要建索引
6.用改造后的语句实验一下,只需要10ms 降低了近200倍!
1 2 3 4 5 6 7 8 9 10 11
+----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 1 | PRIMARY | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | Using where | | 2 | UNION | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 2 | UNION | ec | eq_ref | PRIMARY,emp_certificate_empid | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | | | 2 | UNION | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.ec.emp_id | 1 | Using where | | NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ 53 rows in set (0.01 sec)
select c.id, c.name, c.position, c.sex, c.phone, c.office_phone, c.feature_info, c.birthday, c.creator_id, c.is_keyperson, c.giveup_reason, c.status, c.data_source, from_unixtime(c.created_time) as created_time, from_unixtime(c.last_modified) as last_modified, c.last_modified_user_id from contact c where exists ( select 1 from contact_branch cb inner join branch_user bu on cb.branch_id = bu.branch_id and bu.status in ( 1, 2) inner join org_emp_info oei on oei.data_id = bu.user_id and oei.node_left >= 2875 and oei.node_right <= 10802 and oei.org_category = - 1 where c.id = cb.contact_id ) order by c.created_time desc limit 0 , 10;
select sql_no_cache c.id, c.name, c.position, c.sex, c.phone, c.office_phone, c.feature_info, c.birthday, c.creator_id, c.is_keyperson, c.giveup_reason, c.status, c.data_source, from_unixtime(c.created_time) as created_time, from_unixtime(c.last_modified) as last_modified, c.last_modified_user_id from contact c where exists ( select 1 from contact_branch cb innerjoin branch_user bu on cb.branch_id = bu.branch_id and bu.status in ( 1, 2) innerjoin org_emp_info oei on oei.data_id = bu.user_id and oei.node_left >= 2875 and oei.node_right <= 2875 and oei.org_category = - 1 where c.id = cb.contact_id ) orderby c.created_time desclimit0 , 10; Empty set (2min18.99 sec)
2 min 18.99 sec!比之前的情况还糟糕很多。由于mysql的nested loop机制,遇到这种情况,基本是无法优化的。这条语句最终也只能交给应用系统去优化自己的逻辑了。
// ArrayList中删除函数源码 publicbooleanremove(Object o){ if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); returntrue; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); returntrue; } } returnfalse; }
// ArrayList中删除函数源码 privatevoidfastRemove(int index){ modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work }
// ArrayList中迭代器函数源码 public Iterator<E> iterator(){ returnnew Itr(); }
// ArrayList中迭代器类源码 privateclassItrimplementsIterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount;
publicbooleanhasNext(){ return cursor != size; }
@SuppressWarnings("unchecked") public E next(){ checkForComodification(); int i = cursor; if (i >= size) thrownew NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) thrownew ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; }
publicvoidremove(){ if (lastRet < 0) thrownew IllegalStateException(); checkForComodification();
@Override @SuppressWarnings("unchecked") publicvoidforEachRemaining(Consumer<? super E> consumer){ Objects.requireNonNull(consumer); finalint size = ArrayList.this.size; int i = cursor; if (i >= size) { return; } final Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { thrownew ConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } // update once at end of iteration to reduce heap write traffic cursor = i; lastRet = i - 1; checkForComodification(); }
finalvoidcheckForComodification(){ if (modCount != expectedModCount) thrownew ConcurrentModificationException(); } }
当执行for (Integer num : nums)语句时,会先调用ArrayList中的iterator()接口生成迭代器,而在初始化Itr类时会先将ArrayList对象中的modCount变量赋给Itr对象中的expectedModCount变量,在调用迭代器的next函数时会先调用checkForComodification函数进行校验,如果expectedModCount和modCount不相等则会抛出ConcurrentModificationException异常。在正常的集合遍历中,一般情况下,我们只使用迭代器中hasNext和next函数,并不会改变expectedModCount或者modCount的值,所以不会有问题,但是如果在遍历中调用了集合中自有的删除函数操作,则会改变modCount的值,从而导致expectedModCount与modCount不相等,进而在调用迭代器的next函数时进行校验不通过产生ConcurrentModificationException异常。而在遍历中调用迭代器的删除函数操作,由于其内部会在删除元素后对expectedModCount重新赋值,使其与modCount值相等,所以在遍历集合的过程中使用迭代器的删除函数操作不会有问题。
finalbooleantransferForSignal(Node node){ /* * If cannot change waitStatus, the node has been cancelled. */ //1. 更新状态为0 if (!compareAndSetWaitStatus(node, Node.CONDITION, 0)) returnfalse;
/* * Splice onto queue and try to set waitStatus of predecessor to * indicate that thread is (probably) waiting. If cancelled or * attempt to set waitStatus fails, wake up to resync (in which * case the waitStatus can be transiently and harmlessly wrong). */ //2.将该节点移入到同步队列中去 Node p = enq(node); int ws = p.waitStatus; if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL)) LockSupport.unpark(node.thread); returntrue; }
使用锁时,线程获取锁是一种悲观锁策略,即假设每一次执行临界区代码都会产生冲突,所以当前线程获取到锁的时候同时也会阻塞其他线程获取该锁。而CAS操作(又称为无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源的时候不会出现冲突,既然不会出现冲突自然而然就不会阻塞其他线程的操作。因此,线程就不会出现阻塞停顿的状态。那么,如果出现冲突了怎么办?无锁操作是使用CAS(compare and swap)又叫做比较交换来鉴别线程是否出现冲突,出现冲突就重试当前操作直到没有冲突为止。
在同步的时候是获取对象的monitor,即获取到对象的锁。那么对象的锁怎么理解?无非就是类似对对象的一个标志,那么这个标志就是存放在Java对象的对象头。Java对象头里的Mark Word里默认的存放的对象的Hashcode,分代年龄和锁标记位。32为JVM Mark Word默认存储结构为(注:java对象头以及下面的锁状态变化摘自《java并发编程的艺术》一书,该书我认为写的足够好,就没在自己组织语言班门弄斧了):
如图在Mark Word会默认存放hasdcode,年龄值以及锁标志位等信息。
Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。对象的MarkWord变化为下图:
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。下图是两个线程同时争夺锁,导致锁膨胀的流程图。
int CANCELLED = 1//节点从同步队列中取消 int SIGNAL = -1//后继节点的线程处于等待状态,如果当前节点释放同步状态会通知后继节点,使得后继节点的线程能够运行; int CONDITION = -2//当前节点进入等待队列中 int PROPAGATE = -3//表示下一次共享式同步状态获取将会无条件传播下去 int INITIAL = 0;//初始状态
privatestaticbooleanshouldParkAfterFailedAcquire(Node pred, Node node){ int ws = pred.waitStatus; if (ws == Node.SIGNAL) /* * This node has already set status asking a release * to signal it, so it can safely park. */ returntrue; if (ws > 0) { /* * Predecessor was cancelled. Skip over predecessors and * indicate retry. */ do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { /* * waitStatus must be 0 or PROPAGATE. Indicate that we * need a signal, but don't park yet. Caller will need to * retry to make sure it cannot acquire before parking. */ compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } returnfalse; }
privatevoidunparkSuccessor(Node node){ /* * If status is negative (i.e., possibly needing signal) try * to clear in anticipation of signalling. It is OK if this * fails or if status is changed by waiting thread. */ int ws = node.waitStatus; if (ws < 0) compareAndSetWaitStatus(node, ws, 0);
/* * Thread to unpark is held in successor, which is normally * just the next node. But if cancelled or apparently null, * traverse backwards from tail to find the actual * non-cancelled successor. */
//头节点的后继节点 Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } if (s != null) //后继节点不为null时唤醒该线程 LockSupport.unpark(s.thread); }
privatevoiddoReleaseShared(){ /* * Ensure that a release propagates, even if there are other * in-progress acquires/releases. This proceeds in the usual * way of trying to unparkSuccessor of head if it needs * signal. But if it does not, status is set to PROPAGATE to * ensure that upon release, propagation continues. * Additionally, we must loop in case a new node is added * while we are doing this. Also, unlike other uses of * unparkSuccessor, we need to know if CAS to reset status * fails, if so rechecking. */ for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) continue; // loop to recheck cases unparkSuccessor(h); } elseif (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) continue; // loop on failed CAS } if (h == head) // loop if head changed break; } }
将一个分支里提交的改变移到基底分支上重放一遍:git rebase,如git rebase master server,将特性分支server提交的改变在基底分支master上重演一遍;使用rebase操作最大的好处是像在单个分支上操作的,提交的修改历史也是一根线;如果想把基于一个特性分支上的另一个特性分支变基到其他分支上,可以使用--onto操作:git rebase --onto,如git rebase --onto master server client;使用rebase操作应该遵循的原则是:一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行rebase操作;