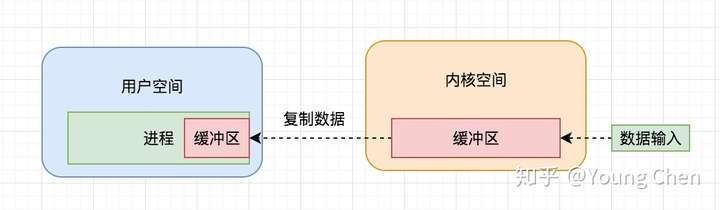
目录:
1.赛马找最快<腾讯高频>
2.砝码称轻重
3.药瓶毒白鼠<腾讯>
4.绳子两头烧
5.犯人猜颜色
6.猴子搬香蕉
7.高楼扔鸡蛋<谷歌>
8.轮流拿石子<头条>
9.蚂蚁走树枝
10.海盗分金币<不常见>
11.三个火枪手
12.囚犯拿豆子
13.学生猜生日<笔试高频>
1. 赛马找最快<腾讯高频题>
**
**
一般有这么几种问法:
25匹马5条跑道找最快的3匹马,需要跑几次?答案:7
64匹马8条跑道找最快的4匹马,需要跑几次?答案:11
25匹马5条跑道找最快的5匹马,需要跑几次?答案:最少8次最多9次
接下来我们看看详细解法:
25匹马5条跑道找最快的3匹马,需要跑几次?

将25匹马分成ABCDE5组,假设每组的排名就是A1>A2>A3>A4>A5,用边相连,这里比赛5次
第6次,每组的第一名进行比赛,可以找出最快的马,这里假设A1>B1>C1>D1>E1
D1,E1肯定进不了前3,直接排除掉
第7次,B1 C1 A2 B2 A3比赛,可以找出第二,第三名
所以最少比赛需要7次
64匹马8条跑道找最快的4匹马,需要跑几次?
第一步
全部马分为8组,每组8匹,每组各跑一次,然后淘汰掉每组的后四名,如下图(需要比赛8场)

第二步
取每组第一名进行一次比赛,然后淘汰最后四名所在组的所有马,如下图(需要比赛1场)

这个时候总冠军已经诞生,它就是A1,蓝域(它不需要比赛了),而其他可能跑得最快的三匹马只可能是下图中的黄域了(A2,A3,A4,B1,B2,B3,C1,C2,D1,共9匹马)

第三步
只要从上面的9匹马中找出跑得最快的三匹马就可以了,但是现在只要8个跑道,怎么办?那就随机选出8匹马进行一次比赛吧(需要比赛一场)
第四步
上面比赛完,选出了前三名,但是9匹马中还有一匹马没跑呢,它可能是一个潜力股啊,那就和前三名比一比吧,这四匹马比一场,选出前三名。最后加上总冠军,跑得最快的四匹马诞生了!!!(需要一场比赛)
最后,一共需要比赛的场次:8 + 1 + 1 + 1 = 11 场
来源:https://blog.csdn.net/u013829973/article/details/80787928
25匹马5条跑道找最快的5匹马,需要跑几次?
(1) 首先将25匹马分成5组,并分别进行5场比赛之后得到的名次排列如下:
A组: [A1 A2 A3 A4 A5]
B组: [B1 B2 B3 B4 B5]
C组: [C1 C2 C3 C4 C5]
D组: [D1 D2 D3 D4 D5]
E组: [E1 E2 E3 E4 E5]
其中,每个小组最快的马为[A1、B1、C1、D1、E1]。
(2) 将[A1、B1、C1、D1、E1]进行第6场,选出第1名的马,不妨设 A1>B1>C1>D1>E1. 此时第1名的马为A1。
(3) 将[A2、B1、C1、D1、E1]进行第7场,此时选择出来的必定是第2名的马,不妨假设为B1。因为这5匹马是除去A1之外每个小组当前最快的马。
(3) 进行第8场,选择[A2、B2、C1、D1、E1]角逐出第3名的马。
(4) 依次类推,第9,10场可以分别决出第4,5名的吗。
因此,依照这种竞标赛排序思想,需要10场比赛是一定可以取出前5名的。
仔细想一下,如果需要减少比赛场次,就一定需要在某一次比赛中同时决出2个名次,而且每一场比赛之后,有一些不可能进入前5名的马可以提前出局。 当然要做到这一点,就必须小心选择每一场比赛的马匹。我们在上面的方法基础上进一步思考这个问题,希望能够得到解决。
(1) 首先利用5场比赛角逐出每个小组的排名次序是绝对必要的。
(2) 第6场比赛选出第1名的马也是必不可少的。假如仍然是A1马(A1>B1>C1>D1>E1)。那么此时我们可以得到一个重要的结论:有一些马在前6场比赛之后就决定出局的命运了(下面粉色字体标志出局)。
A组: [A1 A2 A3 A4 A5]
B组: [B1 B2 B3 B4 B5 ]
C组: [C1 C2 C3 C4 C5 ]
D组: [D1 D2 D3 D4 D5 ]
E组: [E1 E2 E3 E4 E5 ]
(3) 第7场比赛是关键,能否同时决出第2,3名的马呢?我们首先做下分析:
在上面的方法中,第7场比赛[A2、B1、C1、D1、E1]是为了决定第2名的马。但是在第6场比赛中我们已经得到(B1>C1>D1>E1),试问?有B1在的比赛,C1、D1、E1还有可能争夺第2名吗? 当然不可能,也就是说第2名只能在A2、B1中出现。实际上只需要2条跑道就可以决出第2名,剩下C1、D1、E1的3条跑道都只能用来凑热闹的吗?
能够优化的关键出来了,我们是否能够通过剩下的3个跑道来决出第3名呢?当然可以,我们来进一步分析第3名的情况?
● 如果A2>B1(即第2名为A2),那么根据第6场比赛中的(B1>C1>D1>E1)。 可以断定第3名只能在A3和B1中产生。
● 如果B1>A2(即第2名为B1),那么可以断定的第3名只能在A2, B2,C1 中产生。
好了,结论也出来了,只要我们把[A2、B1、A3、B2、C1]作为第7场比赛的马,那么这场比赛的第2,3名一定是整个25匹马中的第2,3名。
我们在这里列举出第7场的2,3名次的所有可能情况:
① 第2名=A2,第3名=A3
② 第2名=A2,第3名=B1
③ 第2名=B1,第3名=A2
④ 第2名=B1,第3名=B2
⑤ 第2名=B1,第3名=C1
(4) 第8场比赛很复杂,我们要根据第7场的所有可能的比赛情况进行分析。
① 第2名=A2,第3名=A3。那么此种情况下第4名只能在A4和B1中产生。
● 如果第4名=A4,那么第5名只能在A5、B1中产生。
● 如果第4名=B1,那么第5名只能在A4、B2、C1中产生。
不管结果如何,此种情况下,第4、5名都可以在第8场比赛中决出。其中比赛马匹为[A4、A5、B1、B2、C1]
② 第2名=A2,第3名=B1。那么此种情况下第4名只能在A3、B2、C1中产生。
● 如果第4名=A3,那么第5名只能在A4、B2、C1中产生。
● 如果第4名=B2,那么第5名只能在A3、B3、C1中产生。
● 如果第4名=C1,那么第5名只能在A3、B2、C2、D1中产生。
那么,第4、5名需要在马匹[A3、B2、B3、C1、A4、C2、D1]七匹马中产生,则必须比赛两场才行,也就是到第9场角逐出全部的前5名。
③ 第2名=B1,第3名=A2。那么此种情况下第4名只能在A3、B2、C1中产生。
情况和②一样,必须角逐第9场
④ 第2名=B1,第3名=B2。 那么此种情况下第4名只能在A2、B3、C1中产生。
● 如果第4名=A2,那么第5名只能在A3、B3、C1中产生。
● 如果第4名=B3,那么第5名只能在A2、B4、C1中产生。
● 如果第4名=C1,那么第5名只能在A2、B3、C2、D1中产生。
那么,第4、5名需要在马匹[A2、B3、B4、C1、A3、C2、D1]七匹马中产 生,则必须比赛两场才行,也就是到第9场角逐出全部的前5名。
⑤ 第2名=B1,第3名=C1。那么此种情况下第4名只能在A2、B2、C2、D1中产生。
● 如果第4名=A2,那么第5名只能在A3、B2、C2、D1中产生。
● 如果第4名=B2,那么第5名只能在A2、B3、C2、D1中产生。
● 如果第4名=C2,那么第5名只能在A2、B2、C3、D1中产生。
● 如果第4名=D1,那么第5名只能在A2、B2、C2、D2、E2中产生。
那么,第4、5名需要在马匹[A2、B2、C2、D1、A3、B3、C3、D2、E1]九匹马中 产 生,因此也必须比赛两场,也就是到第9长决出胜负。
总结:最好情况可以在第8场角逐出前5名,最差也可以在第9场搞定。
来源:iteye.com/blog/hxraid-662643
2. 砝码称轻重
这一类的题目有很多 这里只举几个经典的:
\1. 有一个天平,九个砝码,其中一个砝码比另八个要轻一些,问至少要用天平称几次才能将轻的那个找出来? 答案:2次
\2. 十组砝码每组十个,每个砝码都是10g重,但是现在其中有一组砝码每个都只有9g重,现有一个能显示克数的秤,最少称几次能找到轻的那组? 答案:1次
有一个天平,九个砝码,一个轻一些,用天平至少几次能找到轻的?
至少2次:第一次,一边3个,哪边轻就在哪边,一样重就是剩余的3个;
第二次,一边1个,哪边轻就是哪个,一样重就是剩余的那个;
答:至少称2次.
有十组砝码每组十个,每个砝码重10g,其中一组每个只有9g,有能显示克数的秤最少几次能找到轻的那一组砝码?
将砝码分组1~10,第一组拿一个,第二组拿两个以此类推。。第十组拿十个放到秤上称出克数x,则y = 550 - x,第y组就是轻的那组
3. 药瓶毒白鼠
有1000个一模一样的瓶子,其中有999瓶是普通的水,有1瓶是毒药。任何喝下毒药的生命都会在一星期之后死亡。现在你只有10只小白鼠和1个星期的时间,如何检验出哪个瓶子有毒药?
答案:
1、将10只老鼠剁成馅儿,分到1000个瓶盖中,每个瓶盖倒入适量相应瓶子的液体,置于户外,并每天补充适量相应的液体,观察一周,看哪个瓶盖中的肉馅没有腐烂或生蛆。(最好不要这样回答)
2.
首先一共有1000瓶,2的10次方是1024,刚好大于1000,也就是说,1000瓶药品可以使用10位二进制数就可以表示。从第一个开始:
第一瓶 : 00 0000 0001
第二瓶: 00 0000 0010
第三瓶: 00 0000 0011
……
第999瓶: 11 1111 0010
第1000瓶: 11 1111 0011
需要十只老鼠,如果按顺序编号,ABCDEFGHIJ分别代表从低位到高位每一个位。 每只老鼠对应一个二进制位,如果该位上的数字为1,则给老鼠喝瓶里的药。
观察,若死亡的老鼠编号为:ACFGJ,一共死去五只老鼠,则对应的编号为 10 0110 0101,则有毒的药品为该编号的药品,转为十进制数为:613号。(这才是正解,当然前提是老鼠还没被撑死)
4. 绳子两头烧
现有若干不均匀的绳子,烧完这根绳子需要一个小时,问如何准确计时15分钟,30分钟,45分钟,75分钟。。。
15:对折之后两头烧(要求对折之后绑的够紧,否则看45分钟解法)
30:两头烧 45:两根,一根两头烧一根一头烧,两头烧完过了30分钟,立即将第二根另一头点燃,到烧完又过15分钟,加起来45分钟 75:=30+45
。。。
5. 犯人猜颜色
一百个犯人站成一纵列,每人头上随机带上黑色或白色的帽子,各人不知道自己帽子的颜色,但是能看见自己前面所有人帽子的颜色.
然后从最后一个犯人开始,每人只能用同一种声调和音量说一个字:”黑”或”白”,
如果说中了自己帽子的颜色,就存活,说错了就拉出去斩了,
说的答案所有犯人都能听见,
是否说对,其他犯人不知道,
在这之前,所有犯人可以聚在一起商量策略,
问如果犯人都足够聪明而且反应足够快,100个人最大存活率是多少?
答案:这是一道经典推理题
1、最后一个人如果看到奇数顶黑帽子报“黑”否则报“白”,他可能死
2、其他人记住这个值(实际是黑帽奇偶数),在此之后当再听到黑时,黑帽数量减一
3、从倒数第二人开始,就有两个信息:记住的值与看到的值,相同报“白”,不同报“黑”
99人能100%存活,1人50%能活
除此以外,此题还有变种:每个犯人只能看见前面一个人帽子颜色又能最多存活多少人?
答案:在上题基础上,限制了条件,这时上次的方法就不管用了,此时只能约定偶数位犯人说他前一个人的帽子颜色,奇数犯人获取信息100%存活,偶数犯人50几率存活。
6. 猴子搬香蕉
一个小猴子边上有100根香蕉,它要走过50米才能到家,每次它最多搬50根香蕉,(多了就被压死了),它每走
1米就要吃掉一根,请问它最多能把多少根香蕉搬到家里。(提示:他可以把香蕉放下往返的走,但是必须保证它每走一米都能有香蕉吃。也可以走到n米时,放下一些香蕉,拿着n根香蕉走回去重新搬50根。)
答案:这种试题通常有一个迷惑点,让人看不懂题目的意图。此题迷惑点在于:走一米吃一根香蕉,一共走50米,那不是把50根香蕉吃完了吗?如果要回去搬另外50根香蕉,则往回走的时候也要吃香蕉,这样每走一米需要吃掉三根香蕉,走50米岂不是需要150根香蕉?
其实不然,本题关键点在于:猴子搬箱子的过程其实分为两个阶段,第一阶段:来回搬,当香蕉数目大于50根时,猴子每搬一米需要吃掉三根香蕉。第二阶段:香蕉数《=50,直接搬回去。每走一米吃掉1根。
我们分析第一阶段:假如把100根香蕉分为两箱。一箱50根。
第一步,把A箱搬一米,吃一根。
第二步,往回走一米,吃一根。
第三步,把B箱搬一米,吃一根。
这样,把所有香蕉搬走一米需要吃掉三根香蕉。
这样走到第几米的时候,香蕉数刚好小于50呢?
100-(n3)<50 && 100-(n-13)>50
走到16米的时候,吃掉48根香蕉,剩52根香蕉。这步很有意思,它可以直接搬50往前走,也可以再来回搬一次,但结果都是一样的。到17米的时候,猴子还有49根香蕉。这时猴子就轻松啦。直接背着走就行。
第二阶段:
走一米吃一根。
把剩下的50-17=33米走完。还剩49-33=16根香蕉。
7. 高楼扔鸡蛋
有2个鸡蛋,从100层楼上往下扔,以此来测试鸡蛋的硬度。比如鸡蛋在第9层没有摔碎,在第10层摔碎了,那么鸡蛋不会摔碎的临界点就是9层。
问:如何用最少的尝试次数,测试出鸡蛋不会摔碎的临界点?
首先要说明的是这道题你要是一上来就说出正确答案,那说明你的智商不是超过160就是你做过这题。
所以建议你循序渐进的回答,一上来就说最优解可能结果不会让你和面试官满意。
答案:
1.暴力法
举个栗子,最笨的测试方法,是什么样的呢?把其中一个鸡蛋,从第1层开始往下扔。如果在第1层没碎,换到第2层扔;如果在第2层没碎,换到第3层扔…….如果第59层没碎,换到第60层扔;如果第60层碎了,说明不会摔碎的临界点是第59层。
在最坏情况下,这个方法需要扔100次。
二分法
采用类似于二分查找的方法,把鸡蛋从一半楼层(50层)往下扔。
如果第一枚鸡蛋,在50层碎了,第二枚鸡蛋,就从第1层开始扔,一层一层增长,一直扔到第49层。
如果第一枚鸡蛋在50层没碎了,则继续使用二分法,在剩余楼层的一半(75层)往下扔……
这个方法在最坏情况下,需要尝试50次。
3.均匀法
如何让第一枚鸡蛋和第二枚鸡蛋的尝试次数,尽可能均衡呢?
很简单,做一个平方根运算,100的平方根是10。
因此,我们尝试每10层扔一次,第一次从10层扔,第二次从20层扔,第三次从30层……一直扔到100层。
这样的最好情况是在第10层碎掉,尝试次数为 1 + 9 = 10次。
最坏的情况是在第100层碎掉,尝试次数为 10 + 9 = 19次。
不过,这里有一个小小的优化点,我们可以从15层开始扔,接下来从25层、35层扔……一直到95层。
这样最坏情况是在第95层碎掉,尝试次数为 9 + 9 = 18次。
4.最优解法
最优解法是反向思考的经典:如果最优解法在最坏情况下需要扔X次,那第一次在第几层扔最好呢?
答案是:从X层扔
假设最优的尝试次数的x次,为什么第一次扔就要选择第x层呢?
这里的解释会有些烧脑,请小伙伴们坐稳扶好:
假设第一次扔在第x+1层:
如果第一个鸡蛋碎了,那么第二个鸡蛋只能从第1层开始一层一层扔,一直扔到第x层。
这样一来,我们总共尝试了x+1次,和假设尝试x次相悖。由此可见,第一次扔的楼层必须小于x+1层。
假设第一次扔在第x-1层:
如果第一个鸡蛋碎了,那么第二个鸡蛋只能从第1层开始一层一层扔,一直扔到第x-2层。
这样一来,我们总共尝试了x-2+1 = x-1次,虽然没有超出假设次数,但似乎有些过于保守。
假设第一次扔在第x层:
如果第一个鸡蛋碎了,那么第二个鸡蛋只能从第1层开始一层一层扔,一直扔到第x-1层。
这样一来,我们总共尝试了x-1+1 = x次,刚刚好没有超出假设次数。
因此,要想尽量楼层跨度大一些,又要保证不超过假设的尝试次数x,那么第一次扔鸡蛋的最优选择就是第x层。
那么算最坏情况,第二次你只剩下x-1次机会,按照上面的说法,你第二次尝试的位置必然是X+(X-1);
以此类推我们可得:
x + (x-1) + (x-2) + … + 1 = 100
这个方程式不难理解:
左边的多项式是各次扔鸡蛋的楼层跨度之和。由于假设尝试x次,所以这个多项式共有x项。
右边是总的楼层数100。
下面我们来解这个方程:
x + (x-1) + (x-2) + … + 1 = 100 转化为
(x+1)*x/2 = 100
最终x向上取整,得到 x = 14
因此,最优解在最坏情况的尝试次数是14次,第一次扔鸡蛋的楼层也是14层。
最后,让我们把第一个鸡蛋没碎的情况下,所尝试的楼层数完整列举出来:
14,27, 39, 50, 60, 69, 77, 84, 90, 95, 99, 100
举个栗子验证下:
假如鸡蛋不会碎的临界点是65层,那么第一个鸡蛋扔出的楼层是14,27,50,60,69。这时候啪的一声碎了。
第二个鸡蛋继续,从61层开始,61,62,63,64,65,66,啪的一声碎了。
因此得到不会碎的临界点65层,总尝试次数是 6 + 6 = 12 < 14 。
下面是我个人的理解:这个更像是优化版的均匀法,均匀法让你第二次尝试不超过10,但是第一次的位置无法保证(最多要9次,最好一次),这个由于每多一次尝试,楼层间隔就-1,最终使得第一次与第二次的和完全均匀(最差情况)。
但是核心思路是逆向思考,因为即使理解了需要两次的和均匀也很难得到第一次要在哪层楼扔。
一旦理解了这种方法,多少层楼你都不会怕啦~
来源:https://blog.csdn.net/qq_38316721/article/details/81351297
8. 轮流拿石子<头条问过>
问题:一共有N颗石子(或者其他乱七八糟的东西),每次最多取M颗最少取1颗,A,B轮流取,谁最后会获胜?(假设他们每次都取最优解)。
答案:简单的巴什博奕:https://www.cnblogs.com/StrayWolf/p/5396427.html
问题:有若干堆石子,每堆石子的数量是有限的,二个人依次从这些石子堆中拿取任意的石子,至少一个(不能不取),最后一个拿光石子的人胜利。
答案:较复杂的尼姆博弈:https://blog.csdn.net/BBHHTT/article/details/80199541
9. 蚂蚁走树枝
问题:放N只蚂蚁在一条长度为M树枝上,蚂蚁与蚂蚁之间碰到就各自往反方向走,问总距离或者时间。
答案:这个其实就一个诀窍:蚂蚁相碰就往反方向走,可以直接看做没有发生任何事:大家都相当于独立的
A蚂蚁与B蚂蚁相碰后你可以看做没有发生这次碰撞,这样无论是求时间还是距离都很简单了。
10. 海盗分金币
问题:5个海盗抢到了100枚金币,每一颗都一样的大小和价值。
他们决定这么分:
抽签决定自己的号码(1,2,3,4,5)
首先,由1号提出分配方案,然后大家5人进行表决,当半数以上的人同意时(不包括半数,这是重点),按照他的提案进行分配,否则将被扔入大海喂鲨鱼。
如果1号死后,再由2号提出分配方案,然后大家4人进行表决,当且仅当半超过半数的人同意时,按照他的提案进行分配,否则将被扔入大海喂鲨鱼。
依次类推……
假设每一位海盗都足够聪明,并且利益至上,能多分一枚金币绝不少分,那么1号海盗该怎么分金币才能使自己分到最多的金币呢?
答案:
从后向前推,如果1至3号强盗都喂了鲨鱼,只剩4号和5号的话,5号一定投反对票让4号喂鲨鱼,以独吞全部金币。所以,4号惟有支持3号才能保命。
3号知道这一点,就会提出“100,0,0”的分配方案,对4号、5号一毛不拔而将全部金币归为已有,因为他知道4号一无所获但还是会投赞成票,再加上自己一票,他的方案即可通过。
不过,2号推知3号的方案,就会提出“98,0,1,1”的方案,即放弃3号,而给予4号和5号各一枚金币。由于该方案对于4号和5号来说比在3号分配时更为有利,他们将支持他而不希望他出局而由3号来分配。这样,2号将拿走98枚金币。
同样,2号的方案也会被1号所洞悉,1号并将提出(97,0,1,2,0)或(97,0,1,0,2)的方案,即放弃2号,而给3号一枚金币,同时给4号(或5号)2枚金币。由于1号的这一方案对于3号和4号(或5号)来说,相比2号分配时更优,他们将投1号的赞成票,再加上1号自己的票,1号的方案可获通过,97枚金币可轻松落入囊中。这无疑是1号能够获取最大收益的方案了!答案是:1号强盗分给3号1枚金币,分给4号或5号强盗2枚,自己独得97枚。分配方案可写成(97,0,1,2,0)或(97,0,1,0,2)。
此题还有变种:就是只需要一半人同意即可,不需要一半人以上同意方案就可以通过,在其他条件不变的情况下,1号该怎么分配才能获得最多的金币?
答案:类似的推理过程
4号:4号提出的方案的时候肯定是最终方案,因为不管5号同意不同意都能通过,所以4号5号不必担心自己被投入大海。那此时5号获得的金币为0,4号获得的金币为100。
5号:因为4号提方案的时候 ,自己获取的金币为0 。所以只要4号之前的人分配给自己的金币大于0就同意该方案。
4号:如果3号提的方案一定能获得通过(原因:3号给5号的金币大于0, 5号就同意 因此就能通过),那自己获得的金币就为0,所以只要2号让自己获得的金币大于0就会同意。
3号:因为到了自己提方案的时候可以给5号一金币,自己的方案就能通过,但考虑到2号提方案的时候给4号一个金币,2号的方案就会通过,那自己获得的金币就为0。所以只要1号让自己获得的金币大于0就会同意。
2号:因为到了自己提方案的时候只要给4号一金币,就能获得通过,根本就不用顾及3 号 5号同意不同意,所以不管1号怎么提都不会同意。
1号:2号肯定不会同意。但只要给3号一块金币,5号一块金币(因为5号如果不同意,那么4号分配的时候,他什么都拿不到)就能获得通过。
所以答案是 98,0,1,0,1。
类似的问题也可用类似的推理,并不难
11. 三个火枪手
问题:彼此痛恨的甲、乙、丙三个枪手准备决斗。甲枪法最好,十发八中;乙枪法次之,十发六中;丙枪法最差,十发四中。如果三人同时***,并且每人每轮只发一枪;那么枪战后,谁活下来的机会大一些?
答案:
一般人认为甲的枪法好,活下来的可能性大一些。但合乎推理的结论是,枪法最糟糕的丙活下来的几率最大。
那么我们先来分析一下各个枪手的策略。
如同田忌赛马一般,枪手甲一定要对枪手乙先***。因为乙对甲的威胁要比丙对甲的威胁更大,甲应该首先干掉乙,这是甲的最佳策略。
同样的道理,枪手乙的最佳策略是第一枪瞄准甲。乙一旦将甲干掉,乙和丙进行对决,乙胜算的概率自然大很多。
枪手丙的最佳策略也是先对甲***。乙的枪法毕竟比甲差一些,丙先把甲干掉再与乙进行对决,丙的存活概率还是要高一些。
我们根据分析来计算一下三个枪手在上述情况下的存活几率:
第一轮:甲射乙,乙射甲,丙射甲。
甲的活率为24%(40% X 60%)
乙的活率为20%(100% - 80%)
丙的活率为100%(无人射丙)。
由于丙100%存活率,因此根据上轮甲乙存活的情况来计算三人第二轮的存活几率:
情况1:甲活乙死(24% X 80% = 19.2%)
甲射丙,丙射甲:甲的活率为60%,丙的活率为20%。
情况2:乙活甲死(20% X 76% = 15.2%)
乙射丙,丙射乙:乙的活率为60%,丙的活率为40%。
情况3:甲乙同活(24% X 20% = 4.8%)
重复第一轮。
情况4:甲乙同死(76% X 80% = 60.8%)
枪战结束。
据此来计算三人活率:
甲的活率为(19.2% X 60%) + (4.8% X 24%) = 12.672%
乙的活率为(15.2% X 60%) + (4.8% X 20%) = 10.08%
丙的活率为(19.2% X 20%) + (15.2% X 40%) + (4.8% X 100%) + (60.8% X 100%) = 75.52%
通过对两轮枪战的详细概率计算,我们发现枪法最差的丙存活的几率最大,枪法较好的甲和乙的存活几率却远低于丙的存活几率。
来自:https://www.zhihu.com/question/288093713/answer/482192781
12. 囚犯拿豆子
问题:有5个囚犯被***,他们请求上诉,于是法官愿意给他们一个机会。
犯人抽签分好顺序,按序每人从100粒豆子中随意抓取,最多可以全抓,最少可以不抓,可以和别人抓的一样多。
最终,抓的最多的和最少的要被处死。
1、他们都是非常聪明且自私的人。
2、他们的原则是先求保命。如果不能保命,就拉人陪葬。
3、100颗不必都分完。
4、若有重复的情况,则也算最大或最小,一并处死(中间重复不算)。
假设每个犯人都足够聪明,但每个犯人并不知道其他犯人足够聪明。那么,谁活下来的可能性最大?
答案:
不存在“谁活下来的可能性比较大”的问题。实际情况是5个人都要死。答案看起来很扯淡,但推理分析后却发现十分符合逻辑。
根据题意,一号知道有五个人抓豆子,为保性命,他只要让豆子在20颗以内就可以了。但是他足够聪明的话他一定拿20颗,因为无论多拿一颗:2,3,4号的人一定会拿20颗最后死的人就会是最多的1号和最少的5号 还是少拿一颗:2,3,4号拿20个后,5号选择也拿20个拉上1234号垫背。(下面会说为什么多拿少拿也只会相差一颗)
2号是知道1号抓了几颗豆子(20)的。那么,对于2号来说,只有2种选择:与1号一样多,或者不一样多。我们就从这里入手。
情况一,假如2号选择与1号的豆子数不一样多,也就是说2号选择比1号多或者比1号少。
我们先要证明,如果2号选择比1号多或者比1号少,那么他一定会选择比1号只多1颗或者只少1颗。
要证明这个并不算太难。因为每个囚犯的第一选择是先求保命,要保命就要尽量使自己的豆子数既不是最多也不是最少。当2号决定选择比1号多的时候,他已经可以保证自己不是最少,为了尽量使自己不是最多,当然比1号多出来的数量越小越好。因为这个数量如果与一号相差大于1的话,那么3号就有机会抓到的居中数,相差越大,二号成为最多的可能性也就越大。反之,当2号决定选择比1号少的时候,也是同样的道理,他会选择只比1号少1颗。既然2号只会会选择比1号多1颗或者比1号少1颗,那么1、2号的豆子数一定是2个连续的自然数,和一定是2n+1(其中1个人是n,另1人是n+1)。
轮到3号的时候,他可以从剩下的豆子数知道1、2号的数量和,也就不难计算出n的值。而3号也只有2个选择:n颗或者n+1颗。为什么呢?这与上面的证明是一样的道理,保命原则,取最接近的数量,这里不再赘述。
不过,3号选择的时候会有一个特殊情况,在这一情况下,他一定会选择较小的n,而不是较大的n+1。这一特殊情况就是,当3号知道自己选择了n后(已保证自己不是最多),剩下的豆子数由于数量有限,4、5号中一定有人比n要少,这样自己一定可以活下来。计算的话就是 [100-(3n+1)]/2<=n ,不难算出,在这个特殊情况下,n>=20。也就是说,当1、2号选择了20或21颗的时候,3号只要选择20颗,就可以保证自己活下来。
这样一来剩下的豆子只剩39颗,4、5号至少有一人少于20颗的(这个人当然是后选的5号),这样死的将是5号和1、2号中选21颗的那个人。当然,1号、2号肯定不会有人选择21这一“倒霉”的数字(因为他们都是聪明人),这样的话,上述“特殊情况(即3号选择n)”就不会发生了。
综上所述,2345这四个人不难从剩下的豆子数知道前面几个人的数量总和,也就不难进而计算出n的值,而这样一来他们也只有n或者n+1这两种选择。最后的5号也是不难算出n的。在前4个人只选择了2个数字(n和n+1)的情况下,5号已是必死无疑,这时,根据“死也要拉几个垫背”的条件,5号会选择n或n+1,选择5个人一起完蛋。
情况二,如果2号选择了与1号不一样多的话,最终结果是5个人一起死,那么2号只有选择与1号一样多了。
那么1、2号的和就是2n,而3号如果选择n+1或者n -1的话,就又回到第一点的情况去了(前3个人的和是3m+1或3m+2),于是3号也只能选择n ,当然,4号还是只能选n,最后的结果仍旧是5个人一起完蛋。
“最后处死抓的最多和最少的囚犯”严格执行这句话的话,除非有人舍己为人,死二留三。但这是足够聪明且自私的囚犯,所以这五个聪明人的下场是全死,这道题只不过是找了一个处死所有人的借口罢了. . . . . .
变种问题:如果每个囚犯都知道其他囚犯足够聪明,事情会怎么发展?
答案:
这样的情况下囚犯一也会像我们一样推导出前面的结论,那么根据自私的规定,他会直接拿完100个,大家一起完蛋(反正结局已定)
13. 学生猜生日<笔试高频>
这种题目笔试中出现的次数比较多,用排除法比较好解决
1.
小明和小强都是张老师的学生,张老师的生日是M月N日,
2人都知道张老师的生日是下列10组中的一天,张老师把M值告诉了小明,
把N值告诉了小强,张老师问他们知道他的生日是那一天吗?
3月4日 3月5日 3月8日
6月4日 6月7日
9月1日 9月5日
12月1日 12月2日 12月8日
小明说:如果我不知道的话,小强肯定也不知道.
小强说:本来我也不知道,但是现在我知道了.
小明说:哦,那我也知道了.
请根据以上对话推断出张老师的生日是哪一天?
答案:9月1日
排除法:
1.小明肯定小强不知道是哪天,排除所有月份里有单独日的月份:6月和12月<因为如果小强的M是2或者7的话,小强就知道了,所以把6月7日与12月2日排除>,所以小明拿到的是3或者9
2.小强本来不知道,所以小强拿到的不是2或者7,但是小强现在知道了,说明把6月与12月排除后,小强拿到的是1,4,8中的一个<这里小强肯定没拿到5,否则他不会知道是哪天的>
3.小明现在也知道了,说明小明拿到的不是3,否则他不会知道是3月4日还是3月8日的,所以小明拿到的是9才能唯一确定生日
综上,答案是9月1日
2.
小明和小强是赵老师的学生,张老师的生日是M月N日,张老师
把M值告诉小明,N值告诉小强
给他们六个选项
3月1日 3月3日 7月3日 7月5日
9月1日 11月7日
小明说:我猜不出来
小强说:本来我也猜不出来,但是现在我知道了
问:张老师生日多少
答案:3月1日
排除法:
1.小明说猜不出来,说明小明拿到的不是单独出现的9或者11,说明老师生日只能是3月或者7月
2.小强原本不知道,说明小强拿到的不是单独出现的5或者7,说明老是生日是1日或3日
3.小强现在知道了,说明小强拿到的是1,因为如果拿到的是3,那么小强就不知道是3月3日还是7月3日了
综上,老师生日是3月1日
作者:代码不规范,测试两行泪
链接:https://www.nowcoder.com/discuss/262595
来源:牛客网