publicclassSolution{ publicintFibonacci(int n){ if(n == 0){ return0; }elseif(n == 1){ return1; } int sum = 0; int two = 0; int one = 1; for(int i=2;i<=n;i++){ sum = two + one; two = one; one = sum; } return sum; } }
3. 复杂度:
时间复杂度: 空间复杂度:
4. 持续优化
1. 分析
观察上一版发现,sum 只在每次计算第 n 项的时候用一下,其实还可以利用 sum 存储第 n-1 项,例如当计算完 f(5) 时 sum 存储的是 f(5) 的值,当需要计算 f(6) 时,f(6) = f(5) + f(4),sum 存储的 f(5),f(4) 存储在 one 中,由 f(5)-f(3) 得到 如图:
2. 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
publicclassSolution{ publicintFibonacci(int n){ if(n == 0){ return0; }elseif(n == 1){ return1; } int sum = 1; int one = 0; for(int i=2;i<=n;i++){ sum = sum + one; one = sum - one; } return sum; } }
The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect other.
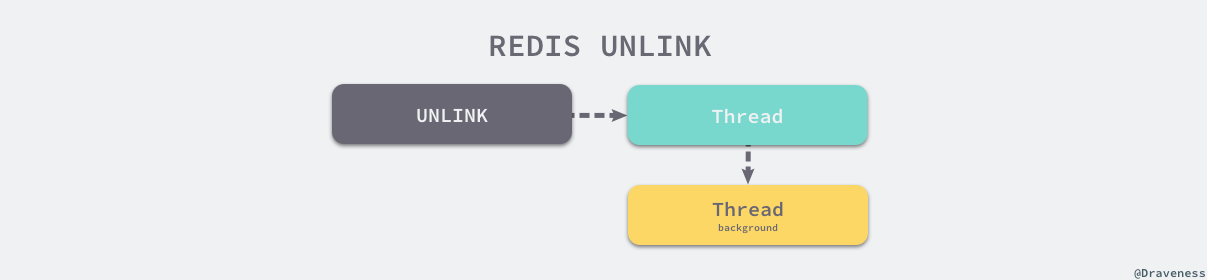
However with Redis 4.0 we started to make Redis more threaded. For now this is limited to deleting objects in the background, and to blocking commands implemented via Redis modules. For the next releases, the plan is to make Redis more and more threaded.
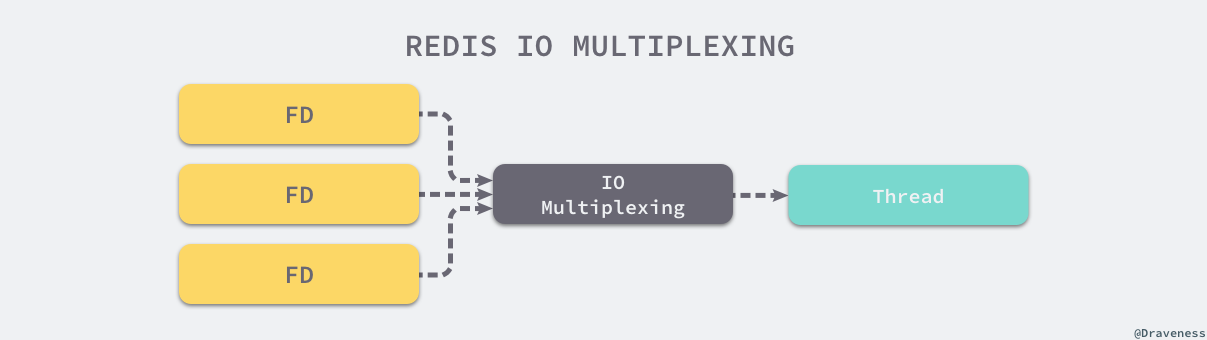
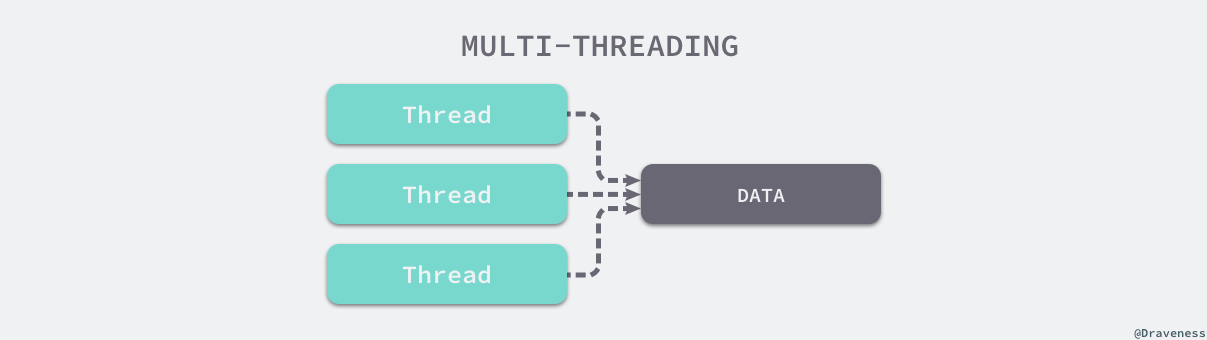
最后要介绍的其实就是 Redis 选择单线程模型的决定性原因 —— 多线程技术能够帮助我们充分利用 CPU 的计算资源来并发的执行不同的任务,但是 CPU 资源往往都不是 Redis 服务器的性能瓶颈。哪怕我们在一个普通的 Linux 服务器上启动 Redis 服务,它也能在 1s 的时间内处理 1,000,000 个用户请求。
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.