publicint[] multiply(int[] A) { int[] B = newint[A.length]; int[] D = newint[A.length]; D[D.length - 1] = 1; for (int i = D.length - 2; i >= 0; i--) { D[i] = D[i + 1] * A[i + 1]; } int C = 1; for (int i = 0; i < B.length; i++) { B[i] = C * D[i]; C *= A[i]; } return B; }
public V put(K key, V value){ if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key);//得到hash值 int i = indexFor(hash, table.length);//找到槽 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
首先 int hash = hash(key); key就是我们之前提到的关键码,我们看看HashMap中的这个hash方法做了些什么:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
finalinthash(Object k){ int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); }
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
int i = indexFor(hash, table.length);找到所谓的槽,也就是记录存在的位置。
1 2 3 4 5 6 7
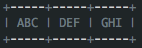
/** * Returns index for hash code h. */ staticintindexFor(int h, int length){ // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
可以看到,indexFor(int h, int length)如何通过hashcode得到记录的位置。indexFor方法内部是一个取模运算,h是我们通过上面的hash方法得到的,length是散列表的长度。HashMap中的散列表是一个数组,通过取模运算能保证indexFor方法的返回值(记录的位置)一定在这个数组内,没有超过其长度。因为h往往是一个很大的数字(int可以表示40亿这么大的数字),而散列表的初始长度是可以由我们指定的(默认是16),另一方面,就算给他这么大的数组,内存也是放不下的。所以取模运算是必须的。经过取模运算得到的才是真正的槽值。
接下来的代码 for (Entry e = table[i]; e != null; e = e.next)就容易理解了。找到记录所对应的槽之后,遍历这个链表直到找到与关键码相同的位置(可能之前已经有以这个关键码为key的value插入)。如果遍历完链表还没有找到这样的值,说明还不存在此关键码对应的记录,直接插入即可:addEntry(hash, key, value, i);.
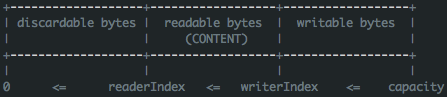
/** * Setup this ChannelBuffer from the list */ privatevoidsetComponents(List<ChannelBuffer> newComponents){ assert !newComponents.isEmpty();
// Clear the cache. lastAccessedComponentId = 0;
// Build the component array. components = new ChannelBuffer[newComponents.size()]; for (int i = 0; i < components.length; i ++) { ChannelBuffer c = newComponents.get(i); if (c.order() != order()) { thrownew IllegalArgumentException( "All buffers must have the same endianness."); }
ReferenceQueue queue = new ReferenceQueue(); List<byte[]> bytes = new ArrayList<>(); PhantomReference<Student> reference = new PhantomReference<Student>(new Student(),queue); new Thread(() -> { for (int i = 0; i < 100;i++ ) { bytes.add(newbyte[1024 * 1024]); } }).start();
new Thread(() -> { while (true) { Reference poll = queue.poll(); if (poll != null) { System.out.println("虚引用被回收了:" + poll); } } }).start(); Scanner scanner = new Scanner(System.in); scanner.hasNext(); }




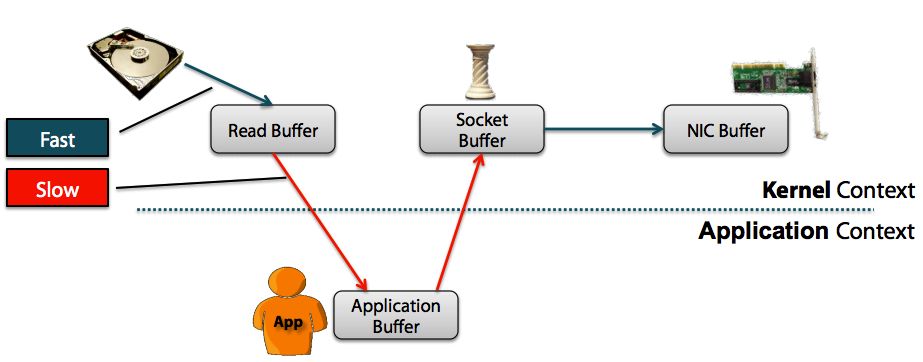
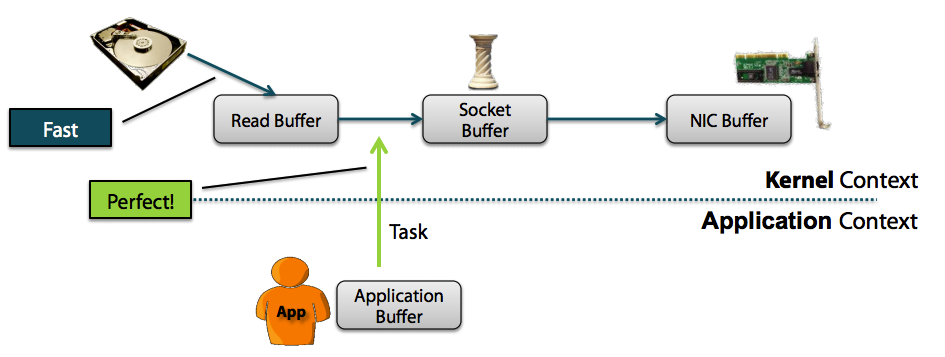
 ##Netty3中零拷贝的实现机制 以下以Netty 3.8.0.Final的源代码来进行说明
##Netty3中零拷贝的实现机制 以下以Netty 3.8.0.Final的源代码来进行说明