hashcode方法会影响jvm性能?听上去天方夜谭,实际上蕴藏着一些微小的原理,接下来让我们走进hashcode方法,一探native方法源头。
默认实现是什么?
调用hashCode方法默认返回的值被称为identity hash code(标识哈希码),接下来我们会用标识哈希码来区分重写hashCode方法。如果一个类重写了hashCode方法,那么通过调用System.identityHashCode(Object o)方法获得标识哈希码。
在hashCode方法注释中,说hashCode一般是通过对象内存地址映射过来的。
1 | As much as is reasonably practical, the hashCode method defined by |
但是了解jvm的同学肯定知道,不管是标记复制算法还是标记整理算法,都会改变对象的内存地址。鉴于jvm重定位对象地址,但该hashCode又不能变化,那么该值一定是被保存在对象的某个地方了。
我们推测,很有可能是在第一次调用hashCode方法时获取当前内存地址,并将其保存在对象的某个地方,当下次调用时,只用从对象的某个地方获取值即可。但这样实际是有问题的,你想想,如果对象被归集到别的内存上了,那在对象以前的内存上创建的新对象其hashCode方法返回的值岂不是和旧对象的一样了?这倒没关系,java规范允许这样做。
以上都是我们的猜测,并没有实锤。我们来看一下源码吧,可恶,hashCode方法是一个本地方法。
1 | public native int hashCode(); |
真正的hashCode方法
hashCode方法的实现依赖于jvm,不同的jvm有不同的实现,我们目前能看到jvm源码就是OpenJDK的源码,OpenJDK的源码大部分和Oracle的JVM源码一致。
OpenJDK定义hashCode的方法在src/share/vm/prims/jvm.h和src/share/vm/prims/jvm.cpp。
jvm.cpp:
1 | 508 JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle)) |
ObjectSynchronizer :: FastHashCode() 也是通过调用identity_hash_value_for方法返回值的,System.identityHashCode()调用的也是这个方法。
1 | 708 intptr_t ObjectSynchronizer::identity_hash_value_for(Handle obj) { |
我们可能会认为 ObjectSynchronizer :: FastHashCode() 会判断当前的hash值是否为0,如果是0则生成一个新的hash值。实际上没那么简单,来看看其中的代码。
1 | 685 mark = monitor->header(); |
上边的片段展示了hash值是如何生成的,可以看到hash值是存放在对象头中的,如果hash值不存在,则使用get_next_hash方法生成。
真正的 identity hash code 生成
在第二节中,我们终于找到了生成hash的最终函数 get_next_hash,这个函数提供了6种生成hash值的方法。
1 | 0. A randomly generated number. |
那么默认用哪一个呢?根据globals.hpp,OpenJDK8默认采用第五种方法。而 OpenJDK7 和 OpenJDK6 都是使用第一种方法,即 随机数生成器。
大家也看到了,JDK的注释算是欺骗了我们,明明在678版本上都是随机生成的值,为什么要引导说是内存地址映射呢?我理解可能以前就是通过第4种方法实现的。
对象头格式
在上一节,我们知道了hash值是放在对象头里的,那就来了解一下对象头的结构吧。
1 | 30 // The markOop describes the header of an object. |
它的格式在32位和64位上略有不同,64位有两种变体,具体取决于是否启用了压缩对象指针。
对象头中偏向锁和hashcode的冲突
在上一节我们看到,normal object和biased object分别存放的是hashcode和java的线程id。因此也就是说如果调用了本地方法hashCode,就会占用偏向锁对象使用的位置,偏向锁将会失效,晋升为轻量级锁。
这个过程我们可以看看这个图:
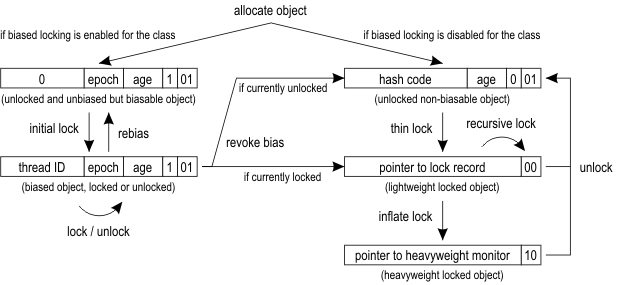
这里我来简单解读一下,首先在jvm启动时,可以使用-XX:+UseBiasedLocking=true参数开启偏向锁。
接下来,如果偏向锁可用,那分配的对象中标记字格式为可包含线程ID,当未锁定时,线程ID为0,第一次获取锁时,线程会把自己的线程ID写到ThreadID字段内,这样,下一次获取锁时直接检查标记字中的线程ID和自身ID是否一致,如果一致就认为获取了锁,因此不需要再次获取锁。
假设这时有别的线程需要竞争锁了,此时该线程会通知持有偏向锁的线程释放锁,假设持有偏向锁的线程已经销毁,则将对象头设置为无锁状态,如果线程活着,则尝试切换,如果不成功,那么锁就会升级为轻量级锁。
这时有个问题来了,如果需要获取对象的identity hash code,偏向锁就会被禁用,然后给原先设置线程ID的位置写入hash值。
如果hash有值,或者偏向锁无法撤销,则会进入轻量级锁。轻量级锁竞争时,每个线程会先将hashCode值保存到自己的栈内存中,然后通过CAS尝试将自己新建的记录空间地址写入到对象头中,谁先写成功谁就拥有了该对象。
轻量级锁竞争失败的线程会自旋尝试获取锁一段时间,一段时间过后还没获取到锁,则升级为重量级锁,没获取锁的线程会被真正阻塞。
总结
- OpenJDK默认的hashCode方法实现和对象内存地址无关,在版本6和7中,它是随机生成的数字,在版本8中,它是基于线程状态的数字。(AZUL-ZING的hashcode是基于地址的)
- 在Hotspot中,hash值会存在标记字中。
- hashCode方法和
System.identityHashCode()会让对象不能使用偏向锁,所以如果想使用偏向锁,那就最好重写hashCode方法。 - 如果大量对象跨线程使用,可以禁用偏向锁。
- 使用
-XX:hashCode=4来修改默认的hash方法实现。